S3 Tables Are Finally Useful!

Estimated Reading Time: 4 minutes
Last Updated: 2025-04-21
Disclaimer: The details described in this post are the results of my own research and investigations. While some effort has been expended in ensuring their accuracy - with ubiquitous references to source material - I cannot guarantee that accuracy. The views and opinions expressed on this blog are my own and do not necessarily reflect the views of any organization I am associated with, past or present.
Back at Re:Invent 2024 when AWS announced first-class support for Iceberg through S3 Tables, the only way you could create them was by spinning up an EMR cluster and running some Spark commands. Believe me, I tried.
Not any more. As of 13th March 2025, AWS released[1][2]:
- Apache Iceberg REST Catalog API integration - you can now create and maintain S3 Tables from any application that implements the Iceberg REST API
- Create and Query table operations using Amazon Athena
Unless your organisation has a lot of different query engines to plug into your Glue catalog, the Athena support is going to be much more interesting. You can now open up the Athena query editor and use CREATE TABLE statements in your S3 Table Catalog and Namespace just like you would any other Iceberg table. This is such a leap forward from the EMR-Spark approach - it significantly speeds up the process, and actually makes S3 Tables a viable choice for your Iceberg workloads.
So, let’s create and query an S3 Table in Athena. For full instructions, follow the tutorial here which will take you through the setup of a table bucket and namespace.
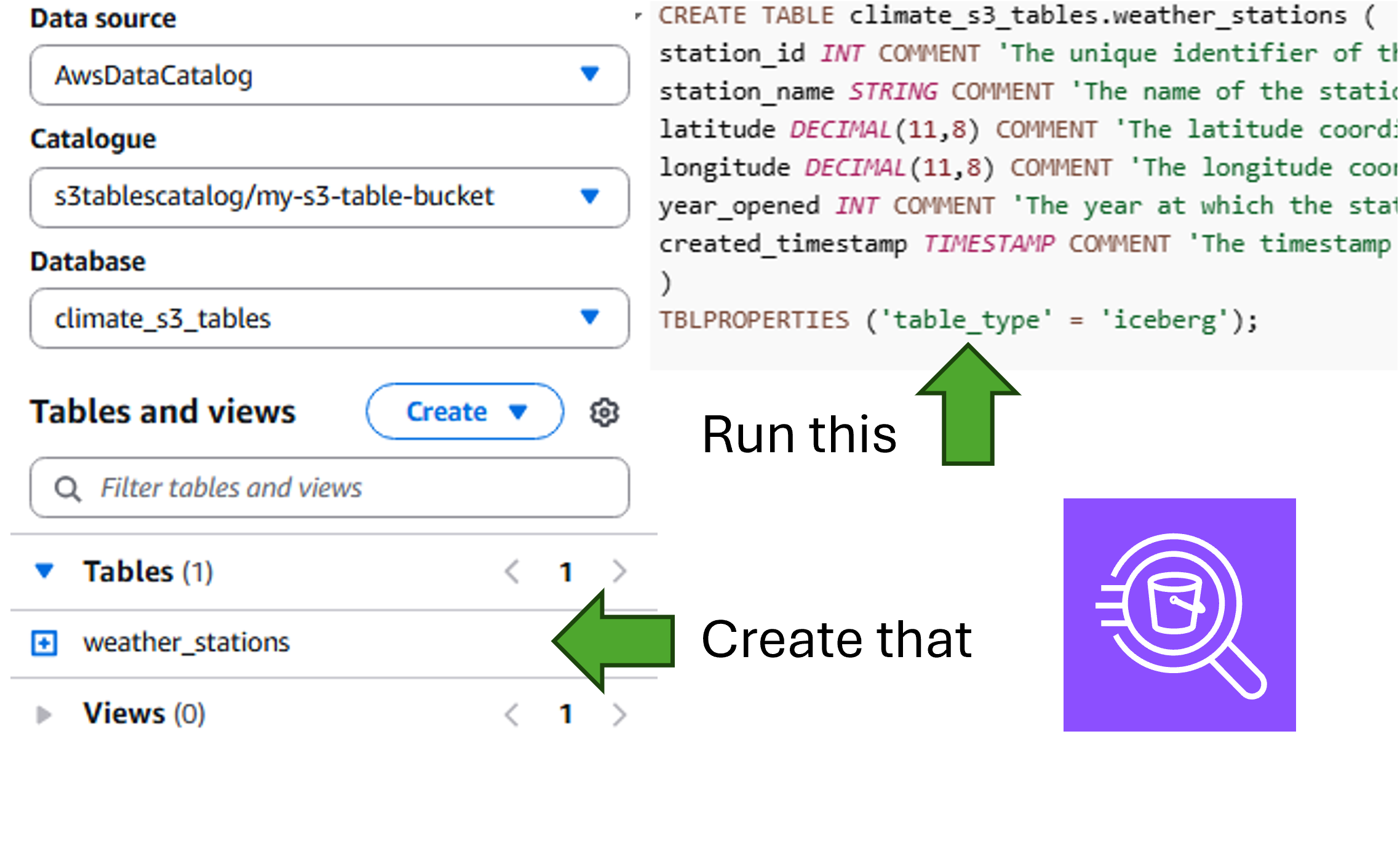
For me, I had already previously created an S3 Table Bucket and a Namespace called climate_s3_tables. In the Athena Query Editor, I simply need to write a CREATE TABLE statement:
CREATE TABLE climate_s3_tables.weather_stations (
station_id INT COMMENT 'The unique identifier of the station',
station_name STRING COMMENT 'The name of the station',
latitude DECIMAL(11,8) COMMENT 'The latitude coordinate of the location of the station',
longitude DECIMAL(11,8) COMMENT 'The longitude coordinate of the location of the station',
year_opened INT COMMENT 'The year at which the station opened',
created_timestamp TIMESTAMP COMMENT 'The timestamp at which this row was created'
)
TBLPROPERTIES ('table_type' = 'iceberg');
This created the table under the namespace climate_s3_tables, which is labelled as a database within Athena.
Since INSERT statements are now supported, let’s insert some data:
INSERT INTO climate_s3_tables.weather_stations (station_id, station_name, latitude, longitude, year_opened, created_timestamp)
VALUES
(101, 'station_1', 10.001, -10.001, 1999, CURRENT_TIMESTAMP),
(202, 'station_2', 20.002, -20.002, 2002, CURRENT_TIMESTAMP),
(303, 'station_3', 30.003, -30.003, 1987, CURRENT_TIMESTAMP),
(404, 'station_4', 40.004, -40.004, 2014, CURRENT_TIMESTAMP),
(505, 'station_5', 50.005, -50.005, 2018, CURRENT_TIMESTAMP);
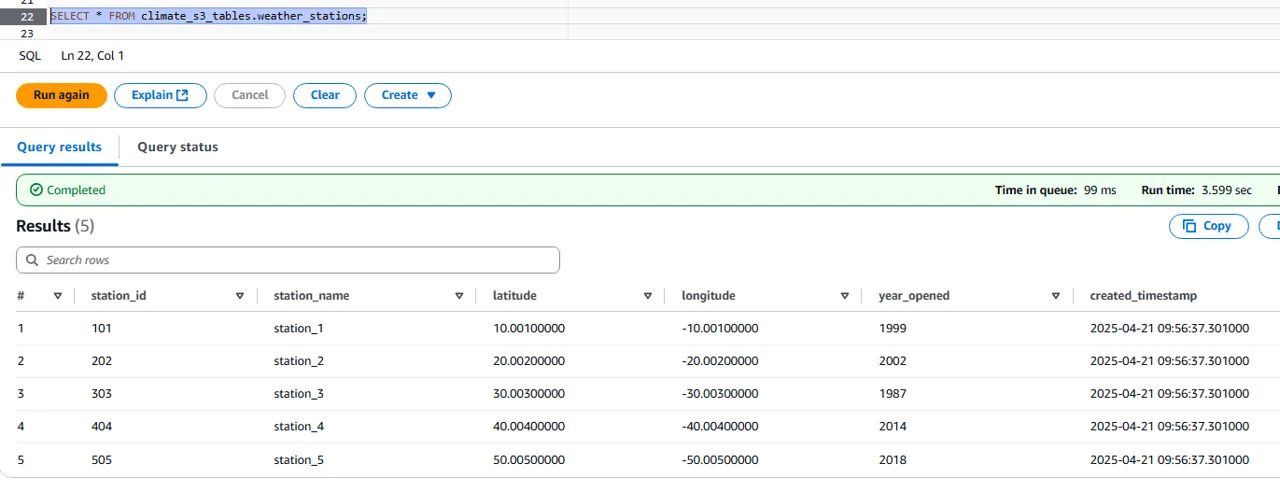
Easy!
Metadata Views
When S3 Tables were first introduced, you could not access the underlying metadata views. This presented a problem because even though S3 Tables should optimize themselves, it is still up to you to ensure that the tables are correctly partitioned.
You can generally tell if your table is improperly partitioned by the number and the size of the files that make up the table. If you have a lot of very small files, then this indicates that you need to rethink your partitioning scheme - ideal Parquet file sizes are between 128MB and 512MB.
With the EMR-Spark approach, I don’t think it was possible to see the underlying metadata files. Now, you can!
SELECT * FROM climate_s3_tables."weather_stations$files";
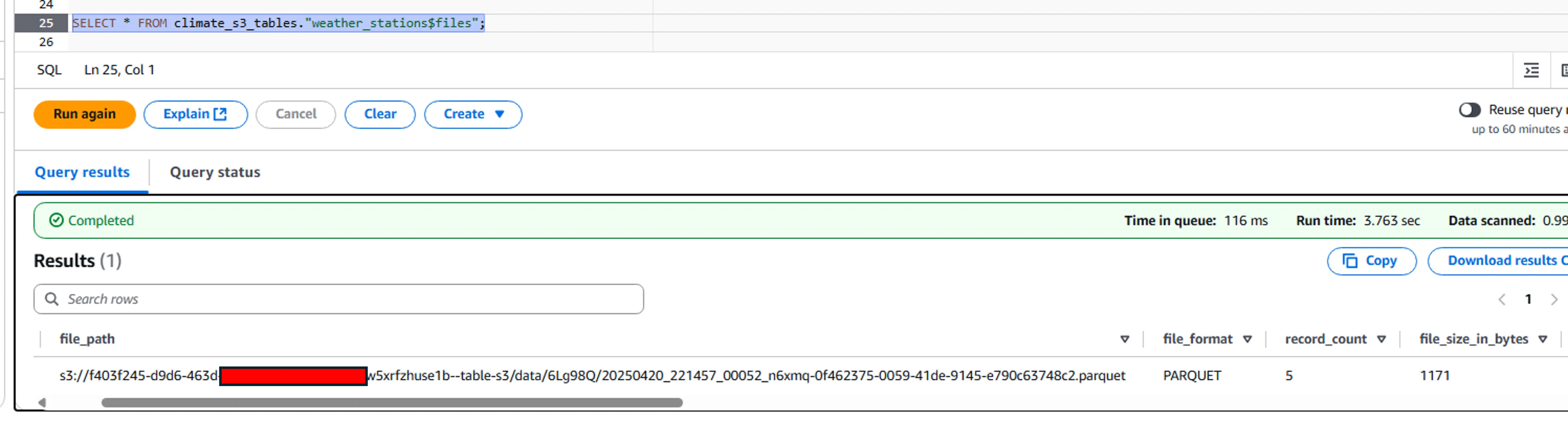
The long bucket name used here is an automatically-generated S3 warehouse location.
Conclusion
The new support for Athena and provision of a REST API endpoint will finally unlock S3 Tables for many organisations. I would still be a little hesitant about using such an evolving service for critical tables just yet, but it’s certainly worth paying attention to developments here, as S3 Tables are quite likely to be the go-to way to create your data lakehouse in the future.
References
[1] - Amazon Web Services (AWS). Amazon S3 Tables add create and query table support in the S3 console. https://aws.amazon.com/about-aws/whats-new/2025/03/amazon-s3-tables-create-query-table-s3-console/
[2] - Amazon Web Services (AWS). Accessing tables using the Amazon S3 Tables Iceberg REST endpoint. https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-integrating-open-source.html