Estimated Reading Time: 20 minutes
Last Updated: 2025-01-02
Disclaimer: The details described in this post are the results of my own research and investigations. While some effort has been expended in
ensuring their accuracy - with ubiquitous references to source material - I cannot guarantee that accuracy.
The views and opinions expressed on this blog are my own and do not necessarily reflect the views of any organization I am associated with, past or present.
In this post we will describe the terms used in an Athena Execution Plan, leveraging the open-source Trino and Presto query engine code where the AWS documentation lacks detail. As Athena’s proprietary integration is built upon Trino (which formerly was a fork of Presto), we can be sure that referencing these codebases is at least reasonably close to how Athena implements the plans.
As stated in the first post on this topic, we will use the term ‘operation’ to represent an execution step taken within the plan, but just be aware that the Trino and Presto code refers to these as Plan nodes instead.
We will use the Distributed Execution Plan that was created for the query in Amazon Athena Execution Plans - Types and Formats:
SELECT t.transaction_date,
c.category_name,
ROUND(SUM(t.total_amount), 2) AS sum_total_amount
FROM supermarket_transactions t
INNER JOIN supermarket_transaction_details td ON t.transaction_id = td.transaction_id
INNER JOIN supermarket_products p ON p.product_id = td.product_id
INNER JOIN supermarket_categories c ON p.category = c.category_name
GROUP BY t.transaction_date,
c.category_name
ORDER BY t.transaction_date DESC,
c.category_name;
The Distribution Execution Plan for this query is:
Query Plan
Fragment 0 [SINGLE]
Output layout: [transaction_date, category, round]
Output partitioning: SINGLE []
Output[columnNames = [transaction_date, category_name, sum_total_amount]]
│ Layout: [transaction_date:date, category:varchar, round:decimal(38,2)]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
│ category_name := category
│ sum_total_amount := round
└─ RemoteMerge[sourceFragmentIds = [1]]
Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
Fragment 1 [ROUND_ROBIN]
Output layout: [round, category, transaction_date]
Output partitioning: SINGLE []
LocalMerge[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
└─ PartialSort[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [2]]
Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
Fragment 2 [HASH]
Output layout: [round, category, transaction_date]
Output partitioning: ROUND_ROBIN []
Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ round := round("sum", 2)
└─ Aggregate[type = FINAL, keys = [transaction_date, category], hash = [$hashvalue]]
│ Layout: [transaction_date:date, category:varchar, $hashvalue:bigint, sum:decimal(38,2)]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ sum := sum("sum_11")
└─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue], arguments = ["transaction_date", "category"]]
│ Layout: [transaction_date:date, category:varchar, sum_11:varbinary, $hashvalue:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [3]]
Layout: [transaction_date:date, category:varchar, sum_11:varbinary, $hashvalue_12:bigint]
Fragment 3 [SOURCE]
Output layout: [transaction_date, category, sum_11, $hashvalue_25]
Output partitioning: HASH [transaction_date, category][$hashvalue_25]
Aggregate[type = PARTIAL, keys = [transaction_date, category], hash = [$hashvalue_25]]
│ Layout: [transaction_date:date, category:varchar, $hashvalue_25:bigint, sum_11:varbinary]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ sum_11 := sum("total_amount")
└─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_25:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ $hashvalue_25 := combine_hash(combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_date"), 0)), COALESCE("$operator$hash_code"("category"), 0))
└─ InnerJoin[criteria = ("category" = "category_name"), hash = [$hashvalue_21, $hashvalue_22], distribution = REPLICATED]
│ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ Distribution: REPLICATED
│ dynamicFilterAssignments = {category_name -> #df_816}
├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_21:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ $hashvalue_21 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("category"), 0))
│ └─ InnerJoin[criteria = ("product_id" = "product_id_4"), hash = [$hashvalue_17, $hashvalue_18], distribution = REPLICATED]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ Distribution: REPLICATED
│ │ dynamicFilterAssignments = {product_id_4 -> #df_817}
│ ├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar, $hashvalue_17:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_17 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("product_id"), 0))
│ │ └─ InnerJoin[criteria = ("transaction_id" = "transaction_id_0"), hash = [$hashvalue_13, $hashvalue_14], distribution = REPLICATED]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ │ Distribution: REPLICATED
│ │ │ dynamicFilterAssignments = {transaction_id_0 -> #df_818}
│ │ ├─ ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transactions, dynamicFilters = {"transaction_id" = #df_818}, projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_id:varchar, transaction_date:date, total_amount:decimal(10,2), $hashvalue_13:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_13 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_id"), 0))
│ │ │ transaction_id := transaction_id:string:REGULAR
│ │ │ transaction_date := transaction_date:date:REGULAR
│ │ │ total_amount := total_amount:decimal(10,2):REGULAR
│ │ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_14], arguments = ["transaction_id_0"]]
│ │ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_14:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ └─ RemoteSource[sourceFragmentIds = [4]]
│ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_15:bigint]
│ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_18], arguments = ["product_id_4"]]
│ │ Layout: [product_id_4:varchar, category:varchar, $hashvalue_18:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ └─ RemoteSource[sourceFragmentIds = [5]]
│ Layout: [product_id_4:varchar, category:varchar, $hashvalue_19:bigint]
└─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_22], arguments = ["category_name"]]
│ Layout: [category_name:varchar, $hashvalue_22:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [6]]
Layout: [category_name:varchar, $hashvalue_23:bigint]
Fragment 4 [SOURCE]
Output layout: [transaction_id_0, product_id, $hashvalue_16]
Output partitioning: BROADCAST []
ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transaction_details, dynamicFilters = {"product_id" = #df_817}, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_16:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_16 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_id_0"), 0))
product_id := product_id:string:REGULAR
transaction_id_0 := transaction_id:string:REGULAR
Fragment 5 [SOURCE]
Output layout: [product_id_4, category, $hashvalue_20]
Output partitioning: BROADCAST []
ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_products, dynamicFilters = {"category" = #df_816}, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [product_id_4:varchar, category:varchar, $hashvalue_20:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_20 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("product_id_4"), 0))
product_id_4 := product_id:string:REGULAR
category := category:string:REGULAR
Fragment 6 [SOURCE]
Output layout: [category_name, $hashvalue_24]
Output partitioning: BROADCAST []
ScanProject[table = awsdatacatalog:aept_db:supermarket_categories, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [category_name:varchar, $hashvalue_24:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_24 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("category_name"), 0))
category_name := category_name:string:REGULAR
For such a small query, the plan produced is substantial. Here is Athena’s graphical version of the plan showing the expected stages of execution:
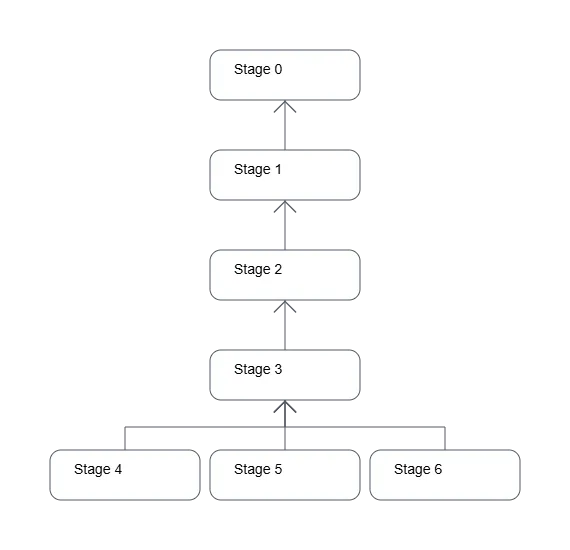
Figure 1: Distributed Execution Plan Graph produced by Amazon Athena
Fragments
As stated in Part 1, a Fragment[1, pg.54] is a section of the execution plan containing a collection of tasks that can be executed independently on one or more worker nodes.
There are different types of fragment based on how data need to be distributed[2]:
-
SINGLE - the tasks of the fragment are executed on a single node, operating on data available on that node
-
HASH - the tasks of the fragment are executed on a fixed number of worker nodes, operating on data that have been distributed via a hash function.
For example, if there are N worker nodes identified by 0 to N-1, a hash function executed on a set of columns of each row - such as the primary key - would produce one of these labels, and that row would be sent to the corresponding worker node. Execution of the tasks in the fragment would occur in parallel on the subset of data for that node
-
ROUND ROBIN - the tasks of the fragment are executed on a fixed number of nodes, operating on data that have been distributed in a round robin fashion.
This means that rows are sent to worker nodes one-by-one in sequence, resulting in all nodes having a roughly equal number of rows, and therefore each node has a roughly equal amount of work to do. All the nodes involved will finish processing at about the same time, reducing the wait time for other nodes to complete their tasks
-
BROADCAST - the tasks of the fragment are executed on a fixed number of nodes, operating on a copy of all rows in the input data.
That is, the full set of input data is copied onto all the worker nodes involved before the fragment tasks begin
-
SOURCE - the tasks of the fragment are executed on the nodes that were used to read from the data source itself.
Indeed, a large dataset is unlikely to be read by a single node. The data are instead divided into chunks that are referenced by metadata called input splits, with each split read by a node, so that the whole dataset is processed across multiple nodes[1, pg.55].
Note that in the Athena[3] and Trino[2] EXPLAIN documentation, the definitions of these types do not specify whether the fragment tasks operate on both the worker and coordinator node types. While we may conclude that the coordinator node accepts fragments of type SINGLE so that it can output results to the calling process[1, pg.50], it is probably safe to say that these fragment types operate on worker nodes, in general.
When speaking about the execution plan, we speak about fragments representing an independent collection of tasks that can be executed in parallel, but when the query itself is executed, the fragments are called stages. The default Amazon Athena distributed plan uses stages in its graphical layout, probably because it simplifies the plan considerably.
Reading the Execution Plan
We are going to read the distributed plan in detail, defining any terminology, starting with the bottom of the hierarchy.
I would recommend that you to open a second window of this post so that you can refer to the plan as we go.
Fragment 6
Fragment 6 corresponds to Stage 6 in the graph, and represents one of three lowest level stages.
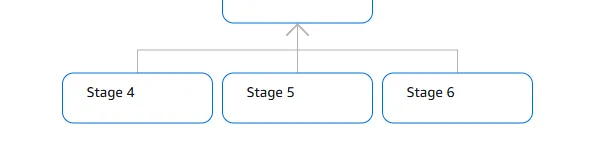
Figure 2: Stages/Fragments 4, 5 and 6 at the bottom of the plan
The text plan for Fragment 6:
Fragment 6 [SOURCE]
Output layout: [category_name, $hashvalue_24]
Output partitioning: BROADCAST []
ScanProject[table = awsdatacatalog:aept_db:supermarket_categories, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [category_name:varchar, $hashvalue_24:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_24 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("category_name"), 0))
category_name := category_name:string:REGULAR
This fragment is of type SOURCE, indicating that the tasks will read from a data source on one or more nodes and will perform operations on those same nodes. One composite operation will be executed - ScanProject - given by the operations:
-
Scan - reads data from the data source, applying “partition pruning generated from the filter predicate”[3].
In this case, it reads all of the data from the CSV file in S3 for this table. If the table were partitioned and a WHERE clause were provided, it may have read only from specified partitions based on that filter predicate
-
Project - selects a subset of columns from the scanned data, perhaps with minor transformations.
The Presto (precursor to Trino) documentation for the corresponding ProjectNode says that this operation “creates columns as functions of existing ones”[4].
We also have a number of properties associated with the ScanProject operation in Fragment 6:
-
table = awsdatacatalog:aept_db:supermarket_categories - the data source is the table aept_db.supermarket_categories in the awsdatacatalog catalog
-
projectLocality - likely indicates whether the projection operation is to be executed on the same worker node or needs to be executed remotely on a different worker node.
Valid values for this are: UNKNOWN, LOCAL or REMOTE[5]
-
protectedBarrier - likely represents the type of synchronization method (barrier) used to ensure that all threads on the worker node reach a certain point before continuing.
As we have protectedBarrier = NONE, this indicates that no synchronization method is used[6]. However, I have been unable to find a reference to this in the Presto and Trino code
-
Layout - the list of columns that will be projected[7]
-
Estimates - the statistics and cost summary for the plan[8].
If there are no statistics for the columns and table, then these values will be empty
-
$hashvalue_24 - the name of the hash column generated by the CombineHash function, calculated for each value of the category_name column that will be used in the join[9]
-
category_name - the joining column that is part of the projection.
-
REGULAR - refers to a Presto/Trino-designated Hive column type. Possible column types are REGULAR, PARTITION_KEY and SYNTHESIZED (hidden column)[10]
Completing the fragment, we have:
- Output Layout - the columns that will be projected as the output of the fragment
- Output Partitioning - the type of System Partition Function that will be used after the fragment tasks are complete
- BROADCAST [] - indicates that the output from the fragment will be sent to a fixed number of worker nodes for further processing
We won’t explore the types of Partitioning today, but the code describing the types is available here.
Fragment 5
Fragment 5 is again of type SOURCE, reading from the aept_db.supermarket_products table.
Fragment 5 [SOURCE]
Output layout: [product_id_4, category, $hashvalue_20]
Output partitioning: BROADCAST []
ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_products, dynamicFilters = {"category" = #df_816}, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [product_id_4:varchar, category:varchar, $hashvalue_20:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_20 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("product_id_4"), 0))
product_id_4 := product_id:string:REGULAR
category := category:string:REGULAR
Most terminology here is the same, except we now have the composite operation of ScanFilterProject, which includes:
- Filter - filters the scanned data based on the predicates stated in WHERE clauses or join conditions
Filter operations can occur via a:
- Static Filter - a filter applied as a result of a predicate from a WHERE clause
- Dynamic Filter - a filter generated at runtime that is pushed down to the table scan to reduce the amount of data that needs to be read.
The filter values come from the output of other fragments on the same or other worker nodes[11].
Indeed, Dynamic Filters are used in this fragment:
- dynamicFilters = {“category” = #df_816} - the output from Fragment 6 containing category name values is broadcast to Fragment 5 tasks and used
to read only the data from aept_db.supermarket_products where category matches one of these category names.
Had supermarket_products been a large, partitioned table based on a columnar file type like Apache Parquet, this would have improved performance considerably. Instead, the underlying data are in a CSV, meaning that the file contents are still read line-by-line.
Trino’s documentation expounds upon dynamic filtering here.
Putting everything together, Fragment 5 has scanned, filtered and projected the product_id, category and a calculated hash column, with its output to be
broadcast to other worker nodes.
Fragment 4
Much like the previous two fragments, Fragment 4 is of type SOURCE, reading from table aept_db.supermarket_transaction_details:
Fragment 4 [SOURCE]
Output layout: [transaction_id_0, product_id, $hashvalue_16]
Output partitioning: BROADCAST []
ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transaction_details, dynamicFilters = {"product_id" = #df_817}, projectLocality = LOCAL, protectedBarrier = NONE]
Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_16:bigint]
Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
$hashvalue_16 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_id_0"), 0))
product_id := product_id:string:REGULAR
transaction_id_0 := transaction_id:string:REGULAR
There’s nothing new here, save for the product_id column from Fragment 5 being used as a dynamic filter for the scan of the table.
The 3 columns - transaction_id, product_id and $hashvalue - are projected and prepared for broadcast.
Fragment 3
Fragment 3 moves us up one level in the hierarchy, combining the output from the previous fragments.
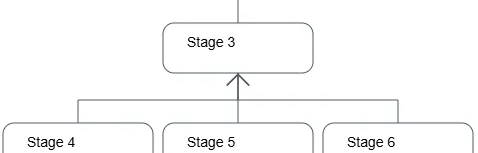
Figure 3: Stage/Fragment 3 begins following completion of Fragments 4, 5 and 6
Fragment 3 [SOURCE]
Output layout: [transaction_date, category, sum_11, $hashvalue_25]
Output partitioning: HASH [transaction_date, category][$hashvalue_25]
Aggregate[type = PARTIAL, keys = [transaction_date, category], hash = [$hashvalue_25]]
│ Layout: [transaction_date:date, category:varchar, $hashvalue_25:bigint, sum_11:varbinary]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ sum_11 := sum("total_amount")
└─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_25:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ $hashvalue_25 := combine_hash(combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_date"), 0)), COALESCE("$operator$hash_code"("category"), 0))
└─ InnerJoin[criteria = ("category" = "category_name"), hash = [$hashvalue_21, $hashvalue_22], distribution = REPLICATED]
│ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ Distribution: REPLICATED
│ dynamicFilterAssignments = {category_name -> #df_816}
├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_21:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ $hashvalue_21 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("category"), 0))
│ └─ InnerJoin[criteria = ("product_id" = "product_id_4"), hash = [$hashvalue_17, $hashvalue_18], distribution = REPLICATED]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ Distribution: REPLICATED
│ │ dynamicFilterAssignments = {product_id_4 -> #df_817}
│ ├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar, $hashvalue_17:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_17 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("product_id"), 0))
│ │ └─ InnerJoin[criteria = ("transaction_id" = "transaction_id_0"), hash = [$hashvalue_13, $hashvalue_14], distribution = REPLICATED]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ │ Distribution: REPLICATED
│ │ │ dynamicFilterAssignments = {transaction_id_0 -> #df_818}
│ │ ├─ ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transactions, dynamicFilters = {"transaction_id" = #df_818}, projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_id:varchar, transaction_date:date, total_amount:decimal(10,2), $hashvalue_13:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_13 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_id"), 0))
│ │ │ transaction_id := transaction_id:string:REGULAR
│ │ │ transaction_date := transaction_date:date:REGULAR
│ │ │ total_amount := total_amount:decimal(10,2):REGULAR
│ │ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_14], arguments = ["transaction_id_0"]]
│ │ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_14:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ └─ RemoteSource[sourceFragmentIds = [4]]
│ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_15:bigint]
│ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_18], arguments = ["product_id_4"]]
│ │ Layout: [product_id_4:varchar, category:varchar, $hashvalue_18:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ └─ RemoteSource[sourceFragmentIds = [5]]
│ Layout: [product_id_4:varchar, category:varchar, $hashvalue_19:bigint]
└─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_22], arguments = ["category_name"]]
│ Layout: [category_name:varchar, $hashvalue_22:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [6]]
Layout: [category_name:varchar, $hashvalue_23:bigint]
Now we’re talking! Fragment 3 is still of type SOURCE, meaning that it is still going to be reading data from a table,
but clearly there are many more steps being undertaken here. We will work our way up from the bottom of the hierarchy.
├─ ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transactions, dynamicFilters = {"transaction_id" = #df_818}, projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_id:varchar, transaction_date:date, total_amount:decimal(10,2), $hashvalue_13:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}/{rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_13 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_id"), 0))
│ │ │ transaction_id := transaction_id:string:REGULAR
│ │ │ transaction_date := transaction_date:date:REGULAR
│ │ │ total_amount := total_amount:decimal(10,2):REGULAR
│ │ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_14], arguments = ["transaction_id_0"]]
│ │ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_14:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ └─ RemoteSource[sourceFragmentIds = [4]]
│ │ Layout: [transaction_id_0:varchar, product_id:varchar, $hashvalue_15:bigint]
Here, we have[2]:
-
RemoteSource - indicates that data from other worker nodes will be provided/transferred.
In this case, the data produced by Fragment 4, specified by sourceFragmentIds = [4], will be used in this section.
-
LocalExchange - refers to the movement of data within a worker node to different tasks, based on a partitioning scheme
-
[partitioning = HASH, hashColumn = [$hashvalue_14], arguments = [“transaction_id_0”]] - the partitioning scheme for the LocalExchange is of type HASH.
A new hash column is produced called $hashvalue_14 with the column transaction_id_0 being used as the parameter to the hash function.
For more information about the logical exchange types (GATHER, REPARTITION, REPLICATE) and distributed exchange types (SINGLE, HASH), AWS provide a helpful breakdown here.
Next, we have another ScanFilterProject operation of the aept_db.supermarket_transactions table, with an internal dynamic filter on the transaction_id from transaction_id_0 values of Fragment 4. The projected columns are transaction_id, transaction_date, total_amount and another hash: $hashvalue_13.
Following this, let’s move up another block:
├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_21:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ $hashvalue_21 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("category"), 0))
│ └─ InnerJoin[criteria = ("product_id" = "product_id_4"), hash = [$hashvalue_17, $hashvalue_18], distribution = REPLICATED]
│ │ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ Distribution: REPLICATED
│ │ dynamicFilterAssignments = {product_id_4 -> #df_817}
│ ├─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar, $hashvalue_17:bigint]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ │ │ $hashvalue_17 := combine_hash(bigint '0', COALESCE("$operator$hash_code"("product_id"), 0))
│ │ └─ InnerJoin[criteria = ("transaction_id" = "transaction_id_0"), hash = [$hashvalue_13, $hashvalue_14], distribution = REPLICATED]
│ │ │ Layout: [transaction_date:date, total_amount:decimal(10,2), product_id:varchar]
│ │ │ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ │ │ Distribution: REPLICATED
│ │ │ dynamicFilterAssignments = {transaction_id_0 -> #df_818}
│ │ ├─ ScanFilterProject[table = awsdatacatalog:aept_db:supermarket_transactions, dynamicFilters = {"transaction_id" = #df_818}, projectLocality = LOCAL, protectedBarrier = NONE]
~ previous plan block here ~
│ └─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_18], arguments = ["product_id_4"]]
│ │ Layout: [product_id_4:varchar, category:varchar, $hashvalue_18:bigint]
│ │ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ └─ RemoteSource[sourceFragmentIds = [5]]
│ Layout: [product_id_4:varchar, category:varchar, $hashvalue_19:bigint]
With the ScanFilterProject of aept_db.supermarket_transactions complete, the first inner join is planned next, joining this table to aept_db.supermarket_transaction_details.
- InnerJoin - indicates that an inner join operation between two tables will be implemented
Notice that the join is achieved through a hash function via the hash values calculated earlier - $hashvalue_13 and $hashvalue_14 - based on transaction_id and transaction_id_0.
- distribution = REPLICATED - indicates that the join distribution is a broadcast, in which the data for the join is replicated onto each worker node
The Trino documentation expands on the types of join distribution and join order here and AWS provides an explanation here too.
Next, the results of the join are projected to the columns: transaction_date, total_amount, product_id and another hash value.
Then, another InnerJoin operation occurs between the projected result set and the result set from Fragment 5. The columns: transaction_date, total_amount, category and new hash value $hashvalue_21, are then projected.
Up next, reading from the bottom, we have a remote source of data for one side of the join: the results of the work from Fragment 6 we examined earlier.
The Fragment 6 data are then used to join to the results from the inner join we reviewed above.
Fragment 3 [SOURCE]
Output layout: [transaction_date, category, sum_11, $hashvalue_25]
Output partitioning: HASH [transaction_date, category][$hashvalue_25]
Aggregate[type = PARTIAL, keys = [transaction_date, category], hash = [$hashvalue_25]]
│ Layout: [transaction_date:date, category:varchar, $hashvalue_25:bigint, sum_11:varbinary]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ sum_11 := sum("total_amount")
└─ Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [transaction_date:date, total_amount:decimal(10,2), category:varchar, $hashvalue_25:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ $hashvalue_25 := combine_hash(combine_hash(bigint '0', COALESCE("$operator$hash_code"("transaction_date"), 0)), COALESCE("$operator$hash_code"("category"), 0))
└─ InnerJoin[criteria = ("category" = "category_name"), hash = [$hashvalue_21, $hashvalue_22], distribution = REPLICATED]
~ previous plan block here ~
└─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue_22], arguments = ["category_name"]]
│ Layout: [category_name:varchar, $hashvalue_22:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [6]]
Layout: [category_name:varchar, $hashvalue_23:bigint]
Following the InnerJoin, the columns: transaction_date, total_amount, category and new hash $hashvalue_25 are projected.
Finally, we have a new operation:
- Aggregate[type = PARTIAL, keys = [transaction_date, category], hash = [$hashvalue_25]] - indicates that an aggregation function will be executed on the result set, grouped by transaction_date and category.
The aggregation type is PARTIAL, meaning that each worker node performs an aggregation on its local subset of the data, which will be combined in the future.
Partial aggregations are faster than full aggregations because they can be executed on multiple worker nodes on a smaller number of rows. Full aggregations need to bring all of the data to a single node to aggregate. Note: there are additional aggregation types of INTERMEDIATE and SINGLE that we won’t cover today.
- sum_11 := sum(“total_amount”) - the aggregation to be implemented by the Aggregate operation is SUM, on the total_amount column
Note that SUM is an additive function, so partial aggregations can be used; some functions such as MEDIAN would not be suitable for partial aggregation.
For Fragment 3, this partial sum is output alongside the grouping of transaction_date and category. The $hashvalue_25 value derived from transaction_date and category is likely projected to make it easier to combine the partial sums from other worker nodes.
- Output partitioning: HASH - the System Partition Function used to partition the data is of type HASH
Fragment 2
Now, we’re closing in on the top of the hierarchy.
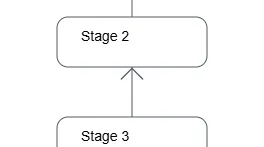
Figure 4: Fragment 2 is provided the results of the partial aggregations from Fragment 3
Fragment 2 [HASH]
Output layout: [round, category, transaction_date]
Output partitioning: ROUND_ROBIN []
Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
│ round := round("sum", 2)
└─ Aggregate[type = FINAL, keys = [transaction_date, category], hash = [$hashvalue]]
│ Layout: [transaction_date:date, category:varchar, $hashvalue:bigint, sum:decimal(38,2)]
│ Estimates: {rows: ? (?), cpu: ?, memory: ?, network: 0B}
│ sum := sum("sum_11")
└─ LocalExchange[partitioning = HASH, hashColumn = [$hashvalue], arguments = ["transaction_date", "category"]]
│ Layout: [transaction_date:date, category:varchar, sum_11:varbinary, $hashvalue:bigint]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [3]]
Layout: [transaction_date:date, category:varchar, sum_11:varbinary, $hashvalue_12:bigint]
Fragment 2 is the first fragment of type HASH; the previous Fragments were of type SOURCE. As a reminder, Fragments of type HASH indicate that
the tasks of the fragment are executed on a fixed number of worker nodes, operating on data that have been distributed via a hash function.
Here, the RemoteSource is the output from Fragment 3. Given that the output partitioning for Fragment 3 was HASH, all partial sums for a given hash (transaction_id, category) would be collocated in a single worker node. Work would still be executed in multiple nodes, but all rows associated with a single hash would be completed on a single node.
Within each node, the LocalExchange distributes data to tasks, ready for another Aggregate operation:
- Aggregate[type=FINAL, keys = [transaction_date, category], hash = [$hashvalue]] - indicates that an aggregation of type FINAL is to be implemented, grouped by transaction_date and category
This aggregation performs:
sum := sum("sum_11")
This represents the sum of the partial sums for the given hash.
In the Project operation, a rounding operation to 2 decimal places is applied on the aggregate.
Finally, the output partitioning from this fragment is ROUND_ROBIN, informing us that the results are to be distributed evenly across all of the worker nodes.
Fragment 1
We have almost reached the top of the hierarchy with fragment 1, the type of which is ROUND_ROBIN.
Figure 5: Fragment 1 is the penultimate fragment in the plan
Fragment 1 [ROUND_ROBIN]
Output layout: [round, category, transaction_date]
Output partitioning: SINGLE []
LocalMerge[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
└─ PartialSort[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]
│ Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
└─ RemoteSource[sourceFragmentIds = [2]]
Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
Fragment 1 accepts evenly distributed data across all worker nodes from Fragment 2. Two unfamiliar operations are then implemented:
-
PartialSort[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]* - likely indicates that the rows from the provided result set on a given node will be ordered by transaction_date in descending order, with nulls ordered last and, category in ascending order, with nulls ordered last.
The data are partially sorted, because each worker node only contains a few of the rows from Fragment 2.
-
LocalMerge[orderBy = [transaction_date DESC NULLS LAST, category ASC NULLS LAST]]*- likely indicates that the results of individual tasks on a worker node are merged together into a single result set on that node.
In this case, multiple tasks on a node may perform the sort on different sets of rows, and LocalMerge would bring these partially sorted results together and order them further.
*Note: I have not been able to find a good reference for these operations, so I cannot verify these definitions.
- Output partitioning: SINGLE - the System Partition Function used to partition the data is of type SINGLE
This means that the partially sorted results from each worker node will be sent to a single node in the next Fragment.
Fragment 0
The end of the line: the top of the hierarchy.
Figure 6: Fragment 0 is the final step before the query results are rendered
Fragment 0 [SINGLE]
Output layout: [transaction_date, category, round]
Output partitioning: SINGLE []
Output[columnNames = [transaction_date, category_name, sum_total_amount]]
│ Layout: [transaction_date:date, category:varchar, round:decimal(38,2)]
│ Estimates: {rows: ? (?), cpu: 0, memory: 0B, network: 0B}
│ category_name := category
│ sum_total_amount := round
└─ RemoteMerge[sourceFragmentIds = [1]]
Layout: [round:decimal(38,2), category:varchar, transaction_date:date]
Fragment 0 [SINGLE] indicates that the tasks for this fragment operate on a single node - the coordinator node[1, pg.49,50].
Indeed, we have:
- RemoteMerge[sourceFragmentIds = [1]]* - likely indicates that data from all worker nodes referenced in sourceFragmentIds = [] are sent across to the node for Fragment 0.
Here, of course, the data from worker nodes involved in Fragment 1 are merged onto this node
Interestingly, there is no further sorting operation executed to order the partially-sorted results, though perhaps this is part of the RemoteMerge.
Then, we have a final operation:
- Output[columnNames = [transaction_date, category_name, sum_total_amount]] - indicates that rows will be returned back to the user or calling process[3].
In this case, the columns that will be sent are transaction_date, category_name and sum_total_amount.
For Amazon Athena, the output from the Athena query engine would be written to S3 and then rendered to the Athena query console.
Congratulations for making it through all that. Of course, the operations we have mentioned above are only a few that may be invoked.
In the next post, we will have a look at some other operations that can appear in the execution plan.
References
[1] - Traverso, M., Fuller, M., Moser, M (2023) Trino: The Definitive Guide. 2nd Edition. Publisher: O’Reilly Media, Inc. https://www.starburst.io/info/oreilly-trino-guide/
[2] - Trino Software Foundation. Trino Documentation - Explain. https://trino.io/docs/current/sql/explain.html
[3] - AWS Documentation. Understand Athena EXPLAIN statement results. https://docs.aws.amazon.com/athena/latest/ug/athena-explain-statement-understanding.html
[4] - PrestoDB/Presto Github - Plan Nodes. https://github.com/prestodb/presto/wiki/Plan-nodes
[5] - PrestoDB/Presto Github - Project Nodes. https://github.com/prestodb/presto/blob/master/presto-spi/src/main/java/com/facebook/presto/spi/plan/ProjectNode.java
[6] - Desai, J. (2020) Barrier Synchronization in Threads. Publisher: Medium.com https://medium.com/@jaydesai36/barrier-synchronization-in-threads-3c56f947047
[7] - TrinoDB/Trino Github - TextRenderer. https://github.com/trinodb/trino/blob/master/core/trino-main/src/main/java/io/trino/sql/planner/planprinter/TextRenderer.java
[8] - TrinoDB/Trino Github - PlanNodeStatsAndCostSummary. https://github.com/trinodb/trino/blob/master/core/trino-main/src/main/java/io/trino/cost/PlanNodeStatsAndCostSummary.java#L22
[9] - TrinoDB/Trino Github - CombineHashFunction. https://github.com/trinodb/trino/blob/master/core/trino-main/src/main/java/io/trino/operator/scalar/CombineHashFunction.java#L27
[10] - TrinoDB/Trino Github - HiveColumnHandle. https://github.com/trinodb/trino/blob/master/plugin/trino-hive/src/main/java/io/trino/plugin/hive/HiveColumnHandle.java
[11] - Trino Documentation. Dynamic Filtering. https://trino.io/docs/current/admin/dynamic-filtering.html \

